O que é engenharia de dados?
O propósito desse texto é descrever brevemente o que é engenharia de dados e seu ciclo de vida utilizando o livro Fundamentos de Engenharia de Dados do Joe Reis e Matt Housley como base.
O que é engenharia de dados?
Engenharia de dados não é exatamente uma coisa nova e já existia de alguma forma em empresas, mas tomou mais foco e cresceu mais ou menos no mesmo período em que big data e ciências de dados começaram a aparecer nos holofotes da bolha tech.
De forma resumida, podemos dizer que pessoas engenheiras de dados configuram e operam a infraestrutura de dados de um empresa, preparando esses dados para analistas de dados, cientistas de dados, etc. Segundo Reis e Housley:
Engenharia de dados é o desenvolvimento, implementação e manutenção de sistemas e processos que recebem dados brutos e produzem informações consistentes e de alta qualidade que dão suporte a casos de uso posteriores, como análise e aprendizado de máquina. Engenharia de dados é a interseção de segurança, gerenciamento de dados, DataOps, arquitetura de dados, orquestração e engenharia de software. Um engenheiro de dados gerencia o ciclo de vida da engenharia de dados, começando com a obtenção de dados de sistemas de origem e terminando com o fornecimento de dados para casos de uso, como análise ou aprendizado de máquina
Ou seja, engenharia de dados foca em receber ou extrair dados crus e trabalhar esses dados para que possam ser repassados para vários casos de usos. Considerando toda a infrastrutura que isso abarca, é muito comum que as pessoas profissionais da área tenham um background em engenharia de software, já que ferramentas como Python, SQL, Java, Scala, bash, entre outros, são bastante utilizadas aqui.
O ciclo de vida de engenharia de dados
Há uma imagem no livro Fundamentos de Engenharia de Dados que é excelente para visualizar o ciclo de vida de um pipeline de dados:
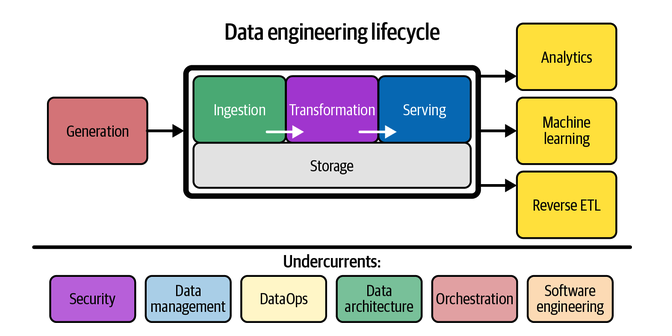
Ou seja, uma pessoa engenheira de dados tem algumas responsabilidades técnicas:
- Geração de dados
- Armazenamento de dados
- Ingestão de dados
- Transformação de dados
- Servir dados para diferentes casos de uso
Os casos de uso, que podem ser vistos como downstream de dados servidos por um pipeline desses, incluem análise de dados, machine learning, ciência de dados, reverse ETL (engenharia reversa de ETL), etc.
Fontes:
REIS, Joe; HOUSLEY, Matt. Fundamentos de Engenharia de Dados. O’Reilly, 2022.