O que é o Apache Cassandra e quando usar?
Hoje falarei um pouco sobre o Apache Cassandra. Usei como base o livro Cassandra The Definitive Guide, bastante utilizado para entender sobre a tecnologia, e um pouco do já clássico Designing Data-Intensive Applications. Abordarei os seguintes tópicos:
O que é o Apache Cassandra?
O Cassandra é um banco de dados NoSQL de código aberto, decentralizado, com escalabilidade elástica, altamente disponível, tolerante a falhas e orientado a linhas particionadas, onde os dados são armazenados em tabelas hash multidimensionais esparsas. Vamos discutir esses pontos.
Bancos NoSQL (not only SQL) são bancos que não seguem os padrões de bancos relacionais, resolvendo problemas um pouco diferentes (em breve farei um texto sobre isso), sendo mais flexíveis (ou totalmente livres) no quesito de schema (como os dados são organizados, restrições lógicas como nome de tabelas, campos e seus tipos, etc), também chamados de schemaless ou de schema on read (schema reforçado apenas na leitura, e não na escrita como os relacionais). No caso do Cassandra podemos dizer que atualmente ele possui um schema flexível.
O Cassandra é capaz de rodar em várias máquinas como um sistema só, por isso é considerado distribuído e foi feito pensando nisso. Faz pouco sentido rodar o Cassandra em um único nó (node).
Grande parte de seu design e base de código são projetados especificamente não apenas para funcionar em muitas máquinas diferentes, mas também para otimizar o desempenho em vários racks de data center e até mesmo para um único cluster Cassandra em execução em data centers geograficamente dispersos. (CARPENTER and HEWITT, 2022)
O Cassandra também é descentralizado porque cada node é idêntico, no sentido de que nenhum node realiza tarefas especializadas como operações de organização; em outras palavras, o Cassandra possui uma arquitetura peer-to-peer. Como nenhum node é especializado podemos dizer que não há um único ponto de falha aqui (single point of failure).
Ser elasticamente escalável significa que o sistema pode continuar servindo para mais usuários sem degradar a performance, podendo escalar e desescalar perfeitamente, sem problemas.
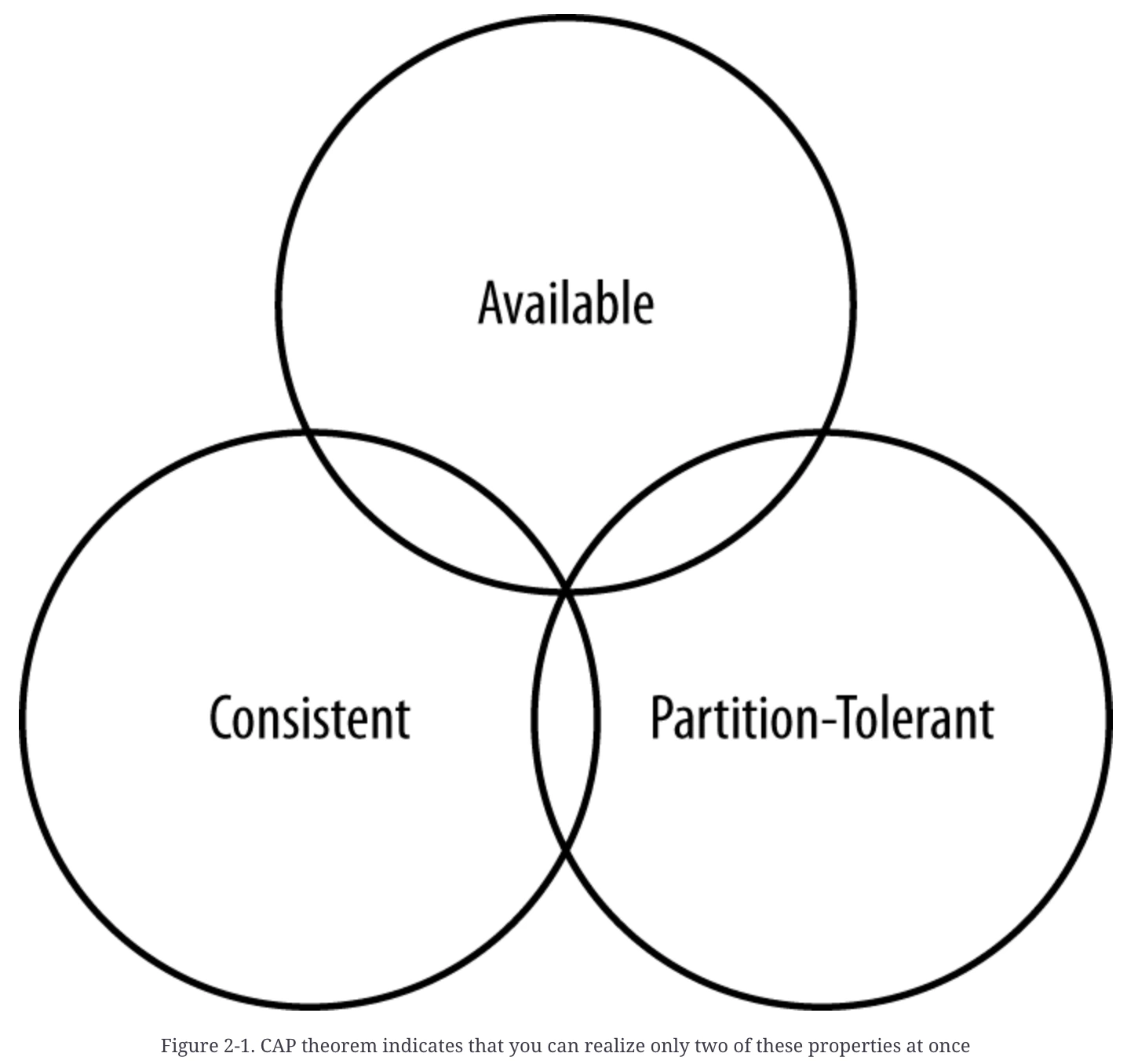
A alta disponibilidade do Cassandra é devido a sua alta capacidade de atender requests. Isso está diretamente relacionado com teorema CAP: assumindo uma situação de partitioning, o Cassandra prioriza availability em detrimento de consistency. Entretanto, vale a pena esclarecer que a consistência no Cassandra é ajustável (tuneable consistency, é uma configuração). Em minhas leituras entendi que atualmente o CAP theorem é como knobs, como se pudéssemos ajustar um pouco mais uma ou outra configuração. Recomendo ler um pouco mais sobre o teorema CAP no capítulo 9 do Designing Data Intensive Application.
“Row-oriented”: o que isso significa?
Na pesquisa para fazer esse artigo e entender melhor o assunto encontrei informações discrepantes, o que me levou a crer que há muita confusão aqui e talvez seja bom evitar algumas fontes da internet. Felizmente estamos seguindo um livro base. Pela definição de Carpenter e Hewitt:
O modelo de dados do Cassandra pode ser descrito como um armazenamento de linha particionado, no qual os dados são armazenados em tabelas hash multidimensionais esparsas. “Esparso” significa que para qualquer linha dada você pode ter uma ou mais colunas, mas cada linha não precisa ter todas as mesmas colunas que outras linhas como ela (como em um modelo relacional). “Particionado” significa que cada linha tem uma chave de partição exclusiva usada para distribuir as linhas em vários armazenamentos de dados. (CARPENTER and HEWITT, 2022)
Ou seja, quando for ter uma “imagem mental” dos dados no Cassandra faz sentido pensar numa linha de banco relacional, dadas as devidas diferenças: cada linha pode ter uma ou mais colunas e não precisa ter as mesmas colunas que outra linha, além de ter uma chave de partição única.
Sobre a confusão de termos que citei anteriormente, você pode ter visto o termo column oriented, mas o livro base desse texto aborda isso:
O Cassandra tem sido frequentemente chamado de banco de dados orientado a colunas ou colunar, mas isso não é tecnicamente correto. O erro é baseado na confusão entre termos que soam semelhantes. Um banco de dados orientado a colunas é aquele em que os dados são armazenados por colunas, ao contrário de bancos de dados relacionais, que armazenam dados em linhas (daí o termo orientado a linhas). Bancos de dados orientados a colunas, como Apache HBase ou Apache Kudu, são projetados para casos de uso analítico. (CARPENTER and HEWITT, 2022)
Quando utilizar o Cassandra?
O Cassandra pode ser um bom fit para o seu projeto caso você precise lidar com:
- Grandes deployments: você precisa de muitos e muitos nodes para a sua aplicação, com a expectativa de escalar muito de forma fácil
- Muita escrita, estatística e análise: sua aplicação precisa de muita estatística e muita escrita concorrent, com poucas leituras. Exemplos: pesquisa documentos, uso de redes sociais, recomendações/avaliações, etc
- Distribuíção geográfica: o Cassandra tem suporte para distribuição geográfica de dados built in
- Nuvem híbrida e deployment multicloud: você precisa fazer deploy não só em múltiplos data centers, mas também em provedores de cloud diferentes. Exemplo: você precisa da maior disponibilidade possível para um aplicativo mission critical e por isso utiliza mais de um proveador (se houver problemas com um provedor ainda haverá o outro)
Fontes:
CARPENTER, Jeff; HEWITT, Eben. Cassandra: The Difinitive Guide. O’Reilly, 2022.
KLEPPMANN, Martin. Designing Data-Intensive Applications. O’Reilly, 2017.