Resumo de conceitos de bancos de dados relacionais
Nesse texto irei abordar de forma resumida alguns conceitos (não é uma lista exaustiva!) que envolvem bancos de dados relacionais:
Transações (transactions)?
Banco de dados relacionais suportam transações (transactions), que são como uma unidade de operação completa num banco relacional, que executa primeiro “virtualmente” e permite que a operação seja desfeita (rollback) se qualquer modificação tenha dado errado. No caso de dar tudo certo com todos os passos da transação, ela pode ser comitada (commited) com segurança no banco. Em outras palavras, uma transação pode ser compreendida como uma transformação de estado que possui as propriedades ACID.
ACID

ACID é um acrônimo para atômico, consistente, isolado e durável. Você pode encontrar a expressão ACID compliant para se referir a um banco que dê suporte a essas propriedades.
- Atômico (atomicity): significa “tudo ou nada” em uma transação. Se uma transação é executada, todas as operações que ela contém precisam ser um sucesso. Ou todas as operações são um sucesso ou a transação falha (pense em OR exclusivo aqui).
- Consitente (consistency): uma transação bem sucedida leva os dados de um estado consistente para outro, sem a possibilidade de usuários verem dados diferentes que não fazem sentido juntos.
- Isolado (isolation): as transações que forem executadas concorrentemente não afetarão umas as outras. Ou seja, se uma transação tentar modificar os mesmos dados que outra, ela terá que esperar.
- Durável (durable): uma transação bem sucedida não será perdida, por exemplo, caso ocorra algum desastre com o data center que contém o banco.
Two-phase commit (2PC)
Lidar com transações é um pouco mais difícil quando temos grandes cargas, com vários usuários realizando muitas operações no banco, e quando vamos escalar horizontalmente (adicionando mais máquinas e agora lidando com um sistema distribuído) para lidar com essa carga passamos a lidar também com transações distribuídas (distributed transactions). Com isso, para manter o banco com propriedades ACID, precisamos ter algum gerenciador de transações para conseguir orquestrar essas transações em vários nodes diferentes.
É aqui que entra a ideia de two-phase commit, que é um algortimo pensado para lidar com consenso entre nodes (máquinas) em um sistema distribuído. O 2PC possui duas fases, duas interações entre hosts: fase de preparação e fase de commit, as quais bloqueiam os recursos associados. Com esse lock (bloqueio) de recursos já podemos imaginar que algumas operações podem levar muito tempo para terminar.
Abaixo uma ilustração do livro Designing Data Intensive Application:
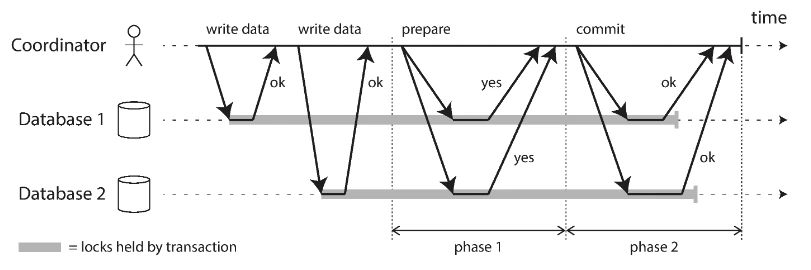
O 2PC espera um node responder, mesmo que o node já tenha morrido e, para não ter um loop rodando para sempre, esperando o node ficar vivo, podemos configurar um timeout. Ainda assim é possivel que ocorra um loop infinito pois um node pode responder OK para commitar a transação, esperar o gerenciador (coordenador) de transações e, se o coordenador está down, o node vai esperar para sempre. Para lidar com esse tipo de problema no mundo relacional temos a ideia de *compensation*, onde a transação é imediatamente comitada, e no caso de um erro ser reportado, uma nova operação é feita para retificar o estado.
Alguns problemas que o 2PC introduz:
- Perda de disponibilidade (availability)
- Maior latência (tempo para chegar de um ponto a outro na rede) em falhas parciais
Para manter o banco relacional ACID compliant é necessário levar em consideração esses problemas que surgem no cenário de um sistema distribuído.
Schema
Você pode representar seus objetos de domínio em um modelo relacional, onde temos entidades e relacionamentos. Geralmente nos referimos ao modelo relacional como schema on write, em contraste com o schema on read de bancos NoSQL, que são mais flexíveis. Schema on write é a característica de ter um schema mais rígido que é reforçado na hora da escrita no banco:
As bases de dados relacionais assumem frequentemente que todos os dados na base de dados estão em conformidade com um esquema: embora este esquema possa ser alterado (através de migrações de esquemas; ou seja, instruções
ALTER), existe exatamente um esquema em vigor. Por outro lado, as bases de dados schema-on-read (“sem esquema”) não impõem um esquema, então a base de dados pode conter uma mistura de formatos de dados mais antigos e mais recentes escritos em diferentes momentos(…) (KLEPPMANN, 2017)
Sharding
Sharding é uma forma de escalar o banco de dados relacional dividindo os dados, ao invés de tê-los em um único servidor, ou tê-los replicados em todos os servidores do cluster. É como se dividíssemos porções dos dados horizontalmente, hospedados separadamente em mais de um node.
É necessário pensar muito bem qual será a lógica para dividir os dados. De nada adianta, por exemplo, dividir dados de forma que as partes mais acessadas (hot spots) continuem juntas, já que não iremos “desafogar”, escalar, o banco de fato.
Existem algumas estratégias bem conhecidas de sharding:
- Por feature (segmentação funcional)
- Por chave (key-based)
Recomendo fortemente a leitura do livro Designing Data Intensive Applications para navegar em assuntos complementares a esse texto:

Fontes:
CARPENTER, Jeff; HEWITT, Eben. Cassandra: The Difinitive Guide. O’Reilly, 2022.
KLEPPMANN, Martin. Designing Data-Intensive Applications. O’Reilly, 2017.