Abordarei os seguintes tópicos:
- O que é um processo?
- O que são threads?
- O que significa I/O bound e CPU bound?
- O que é o GIL do Python?
- O que é concorrência?
- O que é paralelismo?
- A biblioteca asyncio
- A biblioteca threading
- A biblioteca multiprocessing
O que é um processo?
Em computação um processo é uma instância de uma aplicação rodando. Se você abrir uma aplicação no seu computador, como o navegador, essa aplicação vai estar associada a algum processo. Um processo é composto por:
- Contexto de hardware: armazena conteúdo de registradores gerais e específicos da CPU
- Contexto de software: especifica os recursos que podem ser alocados pelo processo
- Espaço de endereçamento: especifica a área da memória que o processo pertence
A imagem a seguir foi retirada do livro do Francis Machado e do Luis Maia:
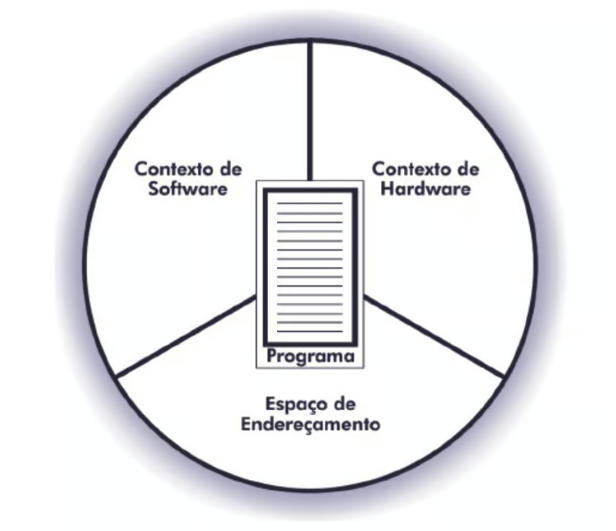
Essas informações são necessárias para a execução de um programa.
O que são threads?
Uma thread é uma sub-rotina de um programa, sendo a menor unidade de execução que um sistema operacional gerencia e componente de um processo.
As várias threads de um processo hipotético podem ser executadas concorrentemente (que entenderemos em breve), compartilhando recursos como memória. Diferentes processos não compartilham esses recursos.
A imagem abaixo foi retirada do Wikipedia:
{kind=link}
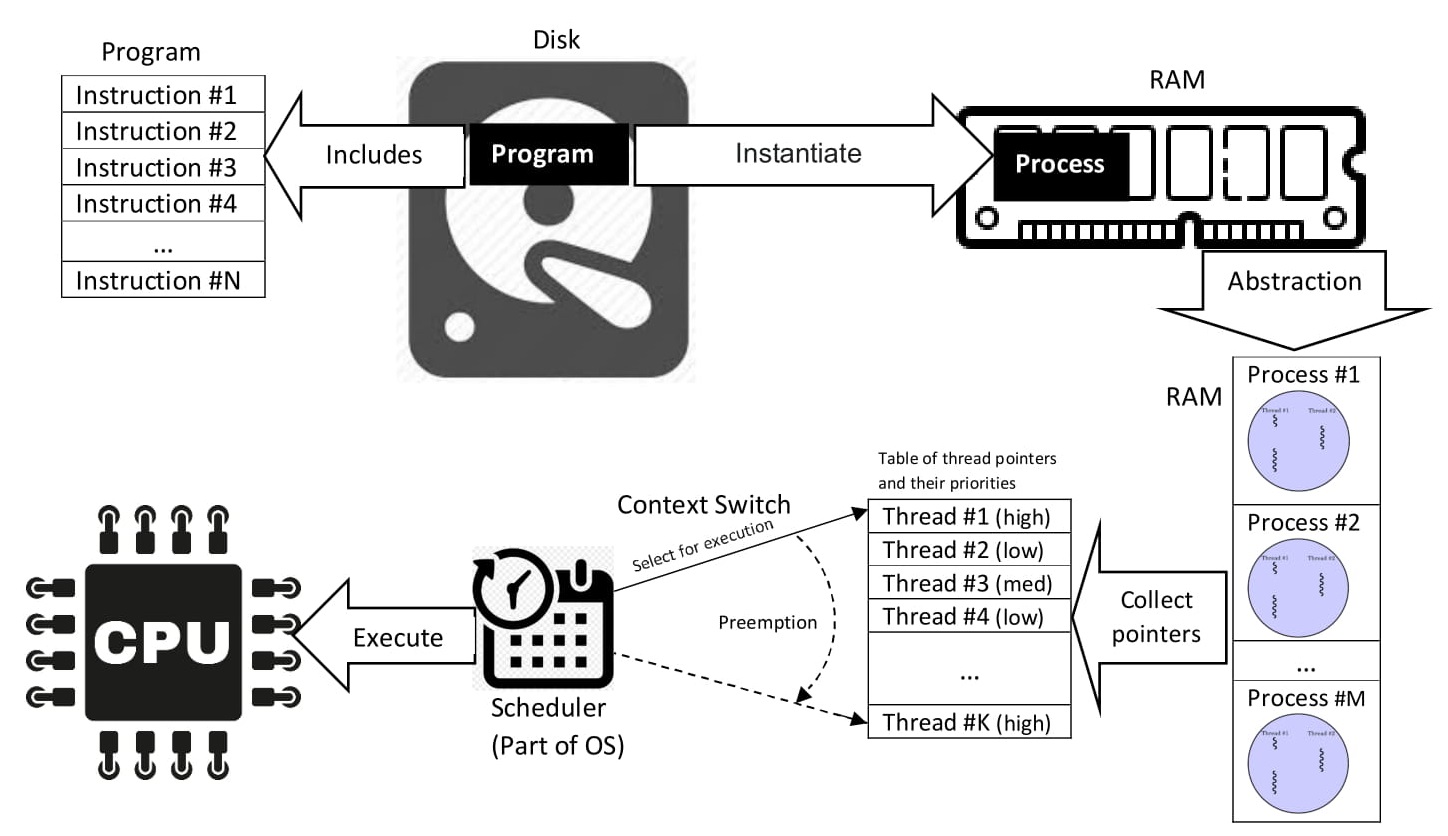
Interpretando a imagem acima, podemos extrair que um programa fica salvo em disco (memória secundária, não-volátil) e inclui várias instruções, podendo ser instanciado (iniciado) em um ou mais processos, e esses por sua vez podem ter várias threads associadas.
O que significa I/O bound e CPU bound?
Essas duas expressões aparecem bastante na discussão sobre concorrência e podem aparecer em português com E/S (entrada/saída) e UCP (unidade central de processamento).
Quando falamos sobre I/O bound e CPU bound estamos falando dos fatores limitantes que previnem uma operação de rodar mais rápido em nosso computador, e podemos encontrar esse dois tipos de operações na mesma codebase.
Uma operação CPU bound faz uso intenso da CPU, e rodará mais rápido se a CPU for mais poderosa. Ou seja, se formos de 2GHz para 4GHz de velocidade de clock essa operação provavelmente rodará mais rápido. Estamos falando aqui de operações que realizam muitas computações, cálculos; a exemplo, como calcular Pi.
Uma operação I/O bound depende da velocidade da rede e velocidade dos dispositivos de entrada e saída. Fazer um request a um servidor web ou ler um arquivo do disco são operações I/O bound.
Ambos os tipos de operações podem se beneficiar do uso de concorrência.
O que é o GIL do Python?
GIL significa global interpreter lock (bloqueio do interpretador global), cujo objetivo é prevenir um processo Python de executar mais de um bytecode de instrução Python ao mesmo tempo. Para rodar uma thread é necessário “adiquirir” o GIL e enquanto uma thread detém o GIL outra thread não pode adiquiri-lo ao mesmo tempo. Isso não significa que não podemos ter mais de uma thread nesse contexto.
Aqui estamos considerando a implementação de referência do Python. O CPython é a implementação padrão do Python, usada como referência de como a linguagem se comporta. Existem outras implementações, como Jython ou IronPython. O GIL está presente no CPython e só recentemente tivemos uma PEP (Python Enhancement Proposal - proposta de melhoria do Python) propondo tornar o GIL opcional.
A ideia do GIL é prevenir race conditions, que podem surgir quando mais de uma thread precisa referenciar um objeto Python ao mesmo tempo. Se mais de uma thread modificar uma variável compartilhada essa variável pode ficar em um estado inesperado. Imagem retirada do livro do Matthew Fowler:
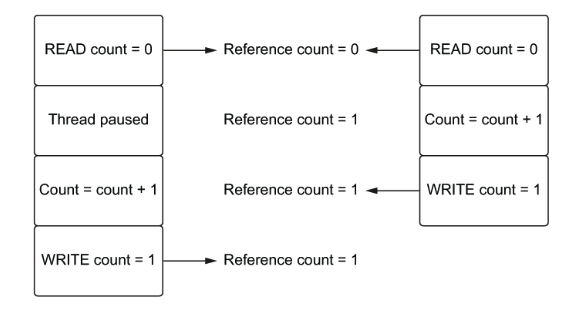
Na imagem acima duas threads estão tentando incrementar uma reference count simultaneamente, e aí ao invés da contagem dar 2, já que as duas estão incrementando 1, o resultado final dá 1 (cada thread é uma coluna).
O que é concorrência?
Concorrência em computação acontece quando lida-se com mais de uma tarefas, sem necessariamente estar executando essas duas tarefas exatamente ao mesmo tempo. Uma frase conhecida do Rob Pyke sobre o assunto:
Concorrência significa lidar com muitas coisas ao mesmo tempo. Paralelismo é fazer muitas coisas ao mesmo tempo.
Pense nessa situação hipotética: se você for fazer dois bolos, pode começar pré-aquecendo o forno e, enquanto isso, prepara a massa do primeiro bolo. Assim que o forno estiver na temperatura correta você já pode colocar a massa do primeiro bolo no forno e, enquanto aguarda o bolo crescer no forno, já pode preparar a massa do segundo bolo. A ideia de concorrência é basicamente essa, você não precisa ficar ocioso, travado, parado, enquanto aguarda uma tarefa completar, você pode fazer um switch e trocar de tarefa.
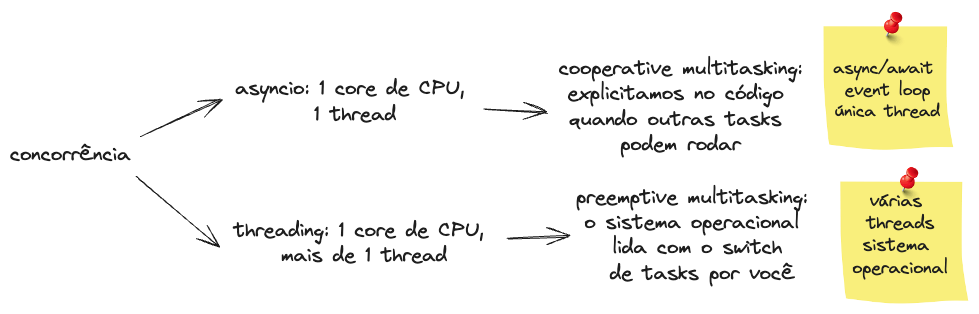
Nesse contexto, temos dois tipos de multitasking:
- Cooperative multitasking: nesse modelo explicitamos no código os pontos onde se pode fazer o switch de tarefas. No Python isso é alcançado com o uso de um event loop, um design pattern comum, usando apenas uma thread e um core de CPU, usando, por exemplo, o
asynciocomasynceawait - Preemptive multitasking: nesse modelo deixamos o sistema operacional lidar com o switch. No Python isso é alcançado com mais de uma thread e um core de CPU usando, por exemplo, a lib
threading
A imagem abaixo ajuda a sumarizar concorrência em Python:
O que é paralelismo?
Paralelismo significa que mais de uma task está sendo executada ao mesmo tempo. Em outras palavras, paralelismo implica concorrência (lidar com mais de uma task), mas concorrência não implica paralelismo (tasks não estão necessariamente sendo executadas em paralelo, ao mesmo tempo). Para que paralelismo seja possível precisamos de mais de um core de CPU.
No Python paralelismo é alcançado, por exemplo, com a lib multiprocessing, onde teremos mais de um processo Python, cada um com seu GIL. A imagem ajuda a ilustrar paralelismo em Python:

A biblioteca asyncio
Existem formas diferentes de se atingir concorrência e paralelismo em Python e podemos utilizar algumas bibliotecas para otimizar nosso código, a depender do tipo de operação que estamos lidando, I/O bound ou CPU bound. O asyncio é uma lib para atingir concorrência usando o async e await. Pela documentação:
O asyncio é usado como uma base para várias estruturas assíncronas do Python que fornecem rede e servidores web de alto desempenho, bibliotecas de conexão de banco de dados, filas de tarefas distribuídas etc.
Como você pode imaginar, essa lib é adequada para otimizar tarefas I/O bound, onde temos tempo de espera de network, escrita em disco, etc. Numa operação CPU bound não há espera, dependemos apenas da velocidade de cálculo da CPU.
A biblioteca threading
A lib threading do Python nos permite operar mais de uma thread, porém, continuamos a lidar com um core de CPU e um processo Python, e lembre-se de que esse é um caso de preemptive multitasking onde o sistema operacional faz a troca de tarefas por nós. A lib também é mais útil para otimizar operações I/O bound.
Sobre o threading, o site Real Python traz alguns pontos importantes:
Porque o sistema operacional está no controle de quando uma task será interrompida e outra task irá começar, qualquer dado que for compartilhado entre as threads precisa ser protegido, ou thread-safe. Infelizmente
requests.Session()não é thread-safe. Existem várias estratégias para fazer o acesso de dados thread-safe a depender de que dado é e como você está usando. Uma delas é usar estruturas de dados thread-safe comoQueuedo móduloqueuedo Python.
Encontramos a documentação do queue aqui.
A biblioteca multiprocessing
Sobre a lib multiprocessing na documentação do Python:
multiprocessingé um pacote que suporta gerar processos usando uma API similar ao módulothreading. O pacotemultiprocessingoferece concorrência tanto local quanto remota, efetivamente desviando o GIL usando sub-processos ao invés de threads. Por isso o módulomultiprocessingpermite o programador aproveitar múltiplos processadores em uma máquina.
Vale apontar que rodar mais de um processo em diferentes cores de CPU não significa desabilitar o GIL, e sim que cada processo terá o seu próprio GIL. Por aproveitar de mais de um core de CPU, compartilhando workloads pesados de CPU entre os múltiplos cores dispiníveis, a lib é mais adequada a CPU bound.
Fontes:
FOWLER, Matthew. Python Concurrency with asyncio. Manning Publications, 2022.
MACHADO, Francis Berenger; MAIA, Luiz Paulo. Arquitetura de Sistemas Operacionais: Incluindo Exercícios com o Simulador SOSIM e Questões do ENADE. Rio de Janeiro: LTC, 2013.
Thread (computing) por Wikipedia
Speed Up Your Python Program With Concurrency por Real Python
]]>